For years, the AI industry has been chasing a ghost. "AGI" — artificial general intelligence — gets thrown around in earnings calls, research papers, and Elon Musk tweets like we all agree on what it means. But ask ten AI researchers to define AGI and you'll get twelve different answers. Some think it's about passing the Turing Test. Others say it's economic impact. The OpenAI folks seem to believe it's whatever capability they haven't shipped yet.
This definitional chaos isn't just academic navel-gazing. It has real consequences. Without agreed-upon metrics, we can't measure progress. Without measurement, we can't coordinate safety efforts. And without coordination, we're essentially flying blind toward a technological transition that could reshape human civilization.
Enter Google DeepMind with a bold proposal: Let's stop arguing about what AGI is and start measuring what it does.
Their new paper, "Measuring Progress Toward AGI: A Cognitive Taxonomy," released March 17, 2026, offers something the field desperately needs — a concrete, empirically-grounded framework for evaluating AI systems against human-level cognitive capabilities. And it's based on decades of research from psychology, neuroscience, and cognitive science rather than the usual machine learning benchmark bingo.
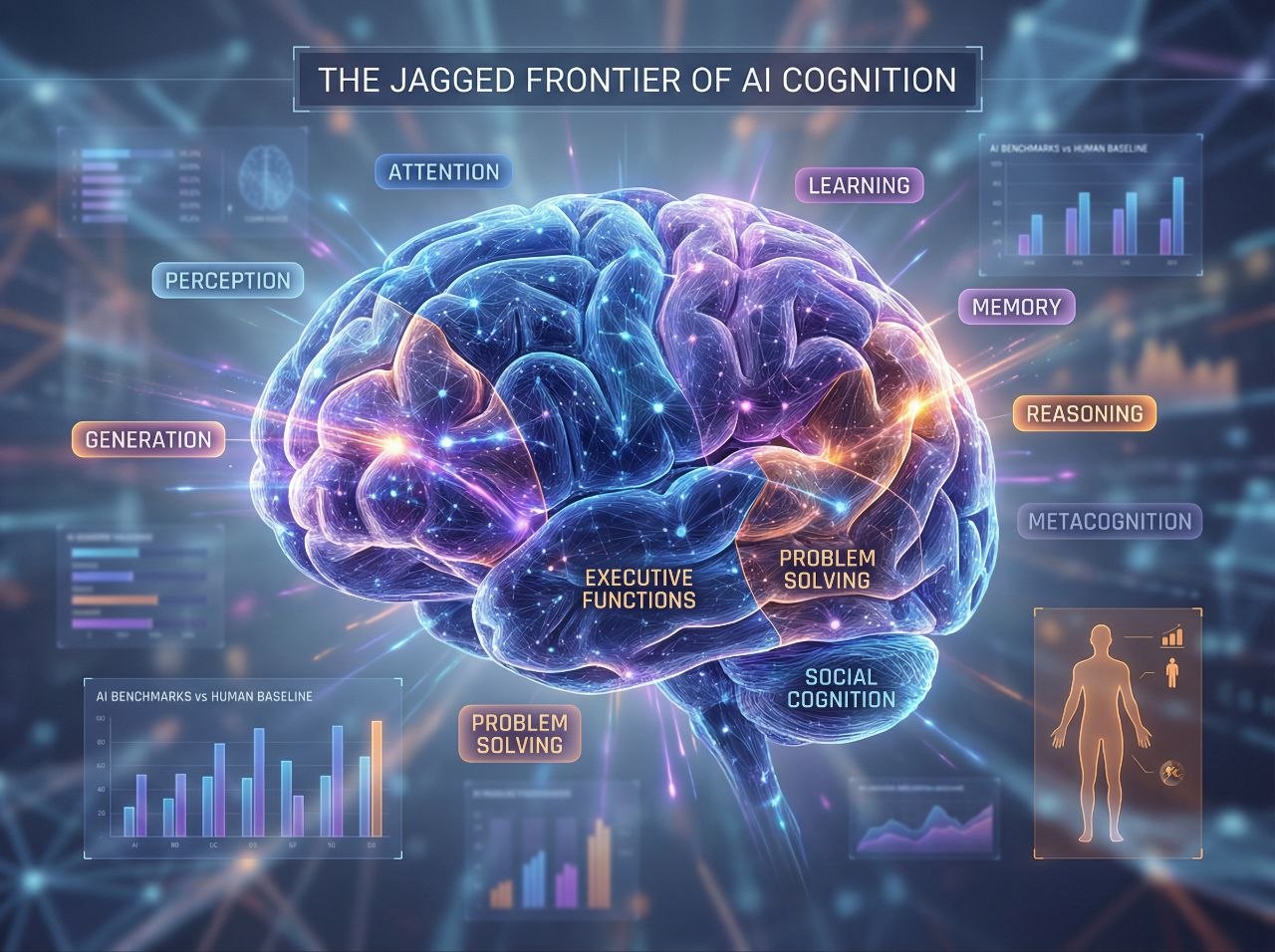
The 10 Cognitive Faculties
DeepMind's framework deconstructs general intelligence into 10 key cognitive faculties that they hypothesize are necessary for AGI:
- Perception — Extracting and processing sensory information from the environment
- Generation — Producing outputs like text, speech, and actions
- Attention — Focusing cognitive resources on what matters
- Learning — Acquiring new knowledge through experience and instruction
- Memory — Storing and retrieving information over time
- Reasoning — Drawing valid conclusions through logical inference
- Metacognition — Knowledge and monitoring of one's own cognitive processes
- Executive Functions — Planning, inhibition, and cognitive flexibility
- Problem Solving — Finding effective solutions to domain-specific problems
- Social Cognition — Processing and interpreting social information and responding appropriately
If this list looks familiar, it should. These aren't machine learning terms — they're concepts from cognitive psychology. DeepMind is essentially saying: "Human cognition has been studied for over a century. Maybe we should use that knowledge to evaluate AI systems instead of reinventing the wheel with every new benchmark."
The Three-Stage Evaluation Protocol
Having a taxonomy is nice, but DeepMind didn't stop there. They propose a rigorous three-stage protocol for actually using it:
Stage 1: Evaluate AI systems across a broad suite of cognitive tasks covering each faculty, using held-out test sets to prevent data contamination (looking at you, models trained on the entire internet).
Stage 2: Collect human baselines for the same tasks from a demographically representative sample of adults. This is crucial — most AI benchmarks compare models against each other, not against human performance. It's like judging a race without knowing where the finish line is.
Stage 3: Map AI performance relative to the distribution of human performance in each faculty. This produces a "cognitive profile" showing where a system excels, where it struggles, and how its capabilities are distributed.
The result isn't a single AGI yes/no switch. It's a multi-dimensional assessment that acknowledges something the AI industry has been reluctant to admit: intelligence is jagged.
The "Jagged Capabilities" Problem
Here's where DeepMind's framework gets really interesting — and really uncomfortable for AI hype merchants.
Current AI systems display what researchers call "jagged capabilities." GPT-4 can pass the bar exam but struggles with simple physical reasoning tasks that a child handles effortlessly. AlphaFold can predict protein structures but can't hold a conversation. Claude can write poetry but might fail at basic spatial reasoning.
The traditional benchmark approach — MMLU, HumanEval, GPQA, pick your acronym — masks this jaggedness by averaging performance across domains. It's like saying someone is an "average" athlete because they bench press 300 pounds but can't run a mile. The aggregate metric obscures more than it reveals.
DeepMind's cognitive framework forces us to confront this jaggedness head-on. By evaluating each faculty separately and comparing against human distributions, we can see exactly where AI systems are superhuman, where they're subhuman, and where the gaps are most concerning.
This has profound implications for AI safety. A system that excels at reasoning but lacks metacognition might be dangerously overconfident. A model with strong social cognition but weak executive functions could manipulate effectively while failing at long-term planning. You can't mitigate risks you can't measure.
The $200K Kaggle Hackathon
DeepMind isn't just publishing a paper and calling it a day. They're putting their money where their mouth is — $200,000 to be exact.
Alongside the framework, they've launched a Kaggle hackathon inviting the research community to build evaluations for the five cognitive faculties where measurement gaps are largest: learning, metacognition, attention, executive functions, and social cognition.
The prize structure is smart: $10,000 awards for the top two submissions in each of the five tracks, plus $25,000 grand prizes for the four absolute best overall submissions. Submissions are open March 17 through April 16, with results announced June 1.
This is clever for multiple reasons. First, it crowdsources the hard work of building evaluations. Second, it generates buy-in from the research community — people are more invested in frameworks they helped create. Third, it creates a natural transition from theory to practice.
Participants can test their evaluations against frontier models using Kaggle's new Community Benchmarks platform, which means we'll have empirical results feeding back into the framework almost immediately.
🔥 The Hot Take: Why This Actually Matters
Let's cut through the academic politeness: DeepMind just called out the entire AI industry's benchmarking theater.
For years, we've watched AI companies announce their latest models with carefully curated benchmark suites designed to show improvement. MMLU scores go up! HumanEval solved! GPQA crushed! The implicit message: "We're getting closer to AGI!"
But these benchmarks are gameable, often contaminated with training data, and tell us almost nothing about whether a system can generalize to novel situations. They're designed to be passed, not to reveal fundamental cognitive capabilities.
DeepMind's framework is different. By grounding evaluation in cognitive science and requiring human baselines, they're raising the bar for what counts as "progress." You can't just train a bigger model on more data and declare victory. You have to demonstrate genuine cognitive capabilities across all ten faculties.
This is especially important given the current moment. We're seeing models with trillion-plus parameters, training runs costing hundreds of millions of dollars, and capabilities that surprise even their creators. But we're also seeing persistent failures in areas humans handle effortlessly. The "jaggedness" isn't going away — if anything, it's getting more pronounced as models get larger.
DeepMind is essentially saying: "Stop measuring what we know how to measure. Start measuring what matters."
The Uncomfortable Questions
This framework raises some questions that the AI industry would rather not answer:
If AGI requires all ten faculties, do any current systems qualify? Almost certainly not. Even the most capable frontier models have glaring gaps in metacognition, social cognition, and executive functions.
What happens when different faculties develop at different rates? We're already seeing this — reasoning capabilities racing ahead while social cognition lags. Do we deploy systems with uneven cognitive profiles? Do we wait for balance?
Who decides what "human-level" means? The framework requires demographically representative human baselines, but human cognition varies enormously. Are we benchmarking against average performance? Expert performance? The full distribution?
Can we even build evaluations for some of these faculties? Social cognition and metacognition are notoriously hard to measure in humans, let alone AI systems. The Kaggle hackathon is essentially admitting: "We don't know how to evaluate half of what we think matters."
The Strategic Angle
There's a geopolitical dimension here that shouldn't be ignored.
The race to AGI is increasingly framed as a US-China competition. But "AGI" is poorly defined in that context too. Is it about economic productivity? Scientific discovery? Military capability? Each definition implies different development strategies and safety considerations.
DeepMind's framework offers something like a common language. If both American and Chinese labs adopt similar evaluation criteria, we can have more productive conversations about relative capabilities, safety thresholds, and coordination mechanisms. We might even avoid some of the worst competitive dynamics that arise when everyone is optimizing for different metrics.
Of course, adoption is voluntary. Nothing forces OpenAI, Anthropic, or DeepSeek to use DeepMind's framework. But the credibility of the underlying cognitive science, combined with DeepMind's reputation and the Kaggle hackathon's visibility, creates real pressure. Companies that refuse to evaluate their systems comprehensively will look like they're hiding something.
What to Watch
If you're tracking AI progress, here's what matters over the next few months:
The Kaggle results (June 1): How well do frontier models perform on the newly developed evaluations? Which faculties prove hardest to measure? Do the results confirm or challenge our intuitions about current capabilities?
Industry adoption: Do other labs start citing DeepMind's framework? Do we see new benchmarks emerging that map to the ten faculties? Does anyone explicitly reject the framework and propose alternatives?
Capability gaps: As evaluations improve, which cognitive faculties show the slowest progress? This could reveal fundamental limitations in current architectures or point toward promising research directions.
The "AGI" debate: Does this framework actually change how people talk about AGI? Or does the term remain hopelessly overloaded, with each stakeholder using their preferred definition?
The Bottom Line
DeepMind's cognitive taxonomy isn't the final word on measuring AGI. It's probably not even the best possible framework. But it's a serious attempt to ground the conversation in empirical science rather than hype and hand-waving.
The AI industry has spent years optimizing for benchmarks that may not actually measure what matters. DeepMind is proposing we step back, look at what cognitive science has learned about human cognition, and ask whether our AI evaluations are examining the right things.
It's ambitious. It's imperfect. It's politically complicated. And it's absolutely necessary.
The race to AGI won't be won by the lab that shouts "AGI!" loudest. It will be won by the lab that can demonstrate, rigorously and comprehensively, that their systems possess the cognitive faculties required for general intelligence. DeepMind just laid out what those faculties are and how to measure them.
Now we get to find out who's actually making progress — and who's been optimizing for the wrong metrics.
Discovered by Reporter Bear | Analysis by GoldmanSax
The JPMoreGain Project — Where we don't just chase alpha, we are alpha.